Every fintech engineering team I've worked with has a version of the same story.
A transaction fails in production. A customer complains or — worse — doesn't complain and just leaves. The team scrambles, finds the cause, ships a hotfix at 11pm, writes a postmortem, and promises to do better.
Three months later, a different bug. Same scramble. Same postmortem.
The problem is not that these teams are bad engineers. The problem is that they are optimising for the wrong thing. They are getting very good at fixing production bugs. They should be getting good at preventing them.
The Cost of Finding Bugs in Production
There is a well-established principle in software engineering called the cost of defects curve: the later in the development cycle a bug is found, the more expensive it is to fix.
A bug caught during development costs 1 unit to fix. A bug caught in QA costs 10 units. A bug caught in production costs 100 units.
In fintech, the multiplier is higher. A production bug doesn't just cost engineering time — it costs:
Revenue: Transactions that fail silently don't generate fees, and in lending or investment products, incorrect calculations directly affect P&L.
Trust: A user who experiences a payment failure has a 60-70% churn probability, even if the failure is resolved quickly. Trust in financial products is earned slowly and lost instantly.
Compliance: Incorrect financial outcomes in regulated markets — incorrect KYC data, wrong settlement amounts, missed audit trails — are not just product bugs. They are regulatory incidents.
Team velocity: Every hour spent firefighting a production incident is an hour not spent building the next feature. At a 10-person fintech startup, two production incidents a month can consume 20-30% of an engineering team's productive capacity.
Why Production Bugs Keep Happening
If teams know all of this, why do production bugs keep happening?
Three reasons.
1. Testing the happy path, not the failure path
Most test suites are written by developers who just built the feature. They test the scenario they had in mind when writing the code — the path where everything works. Edge cases, failure modes, and the scenarios that require two or three things to go wrong simultaneously are rarely covered.
In fintech, the happy path is not where the money is lost. It's in the retry logic after a timeout, the race condition when two requests arrive 50ms apart, the reconciliation gap when a payment gateway callback is delayed by four hours.
2. No domain model for failure
Writing good test cases for financial flows requires knowing how financial systems fail. This is not general software engineering knowledge — it is domain knowledge accumulated through experience.
A QA engineer who has spent three years testing ecommerce applications doesn't automatically know the specific failure modes of a UPI payment flow, an AEPS transaction, or a WealthTech portfolio rebalancing engine. That knowledge comes from exposure, and most teams don't have enough of it.
3. Time pressure collapses testing
In a startup with two-week sprints, testing is typically the last activity before release and the first one to be compressed when a sprint runs long. The result is that QA coverage is inversely correlated with development velocity — the faster you ship, the less you test. This is exactly backwards.
What "Finding Bugs First" Actually Looks Like
Preventing production bugs is not about testing more. It's about testing the right things — specifically the failure modes that cause production incidents.
Here is the framework that has worked across fintech products I have built and tested at scale:
Step 1: Map your critical flows and their failure modes
For every flow in your product that touches money or customer trust, document:
What are the external dependencies? (payment gateways, bank APIs, KYC vendors)
What happens if each dependency is slow, returns an unexpected response, or fails entirely?
What happens if two operations happen simultaneously that your system assumes will be sequential?
What happens at the boundary conditions — minimum amounts, maximum amounts, zero amounts, negative amounts?
This mapping exercise typically takes 2–4 hours per critical flow. Most teams have never done it.
Step 2: Test failure paths explicitly
Once you have the failure mode map, write test cases that deliberately trigger each failure mode. Don't just test "what happens when it works" — test "what happens when it breaks in each specific way."
For a payment API, this means test cases for:
Timeout with retry (does the system handle idempotency correctly?)
Partial success (payment initiated, confirmation not received)
Delayed callback (what state is the transaction in after 30 minutes with no callback?)
Concurrent requests (two requests for the same transaction ID within 100ms)
Invalid amount edge cases (₹0.00, negative amount, amount exceeding configured limits)
Step 3: Automate the regression layer for these scenarios
Manual testing of failure paths is valuable but not repeatable. Once you've identified and tested the critical failure modes, automate those specific scenarios so they run on every deployment.
This is the opposite of how most teams build automation — they automate the happy path first and add edge cases later (if ever). The edge cases should be automated first because they are the ones most likely to regress.
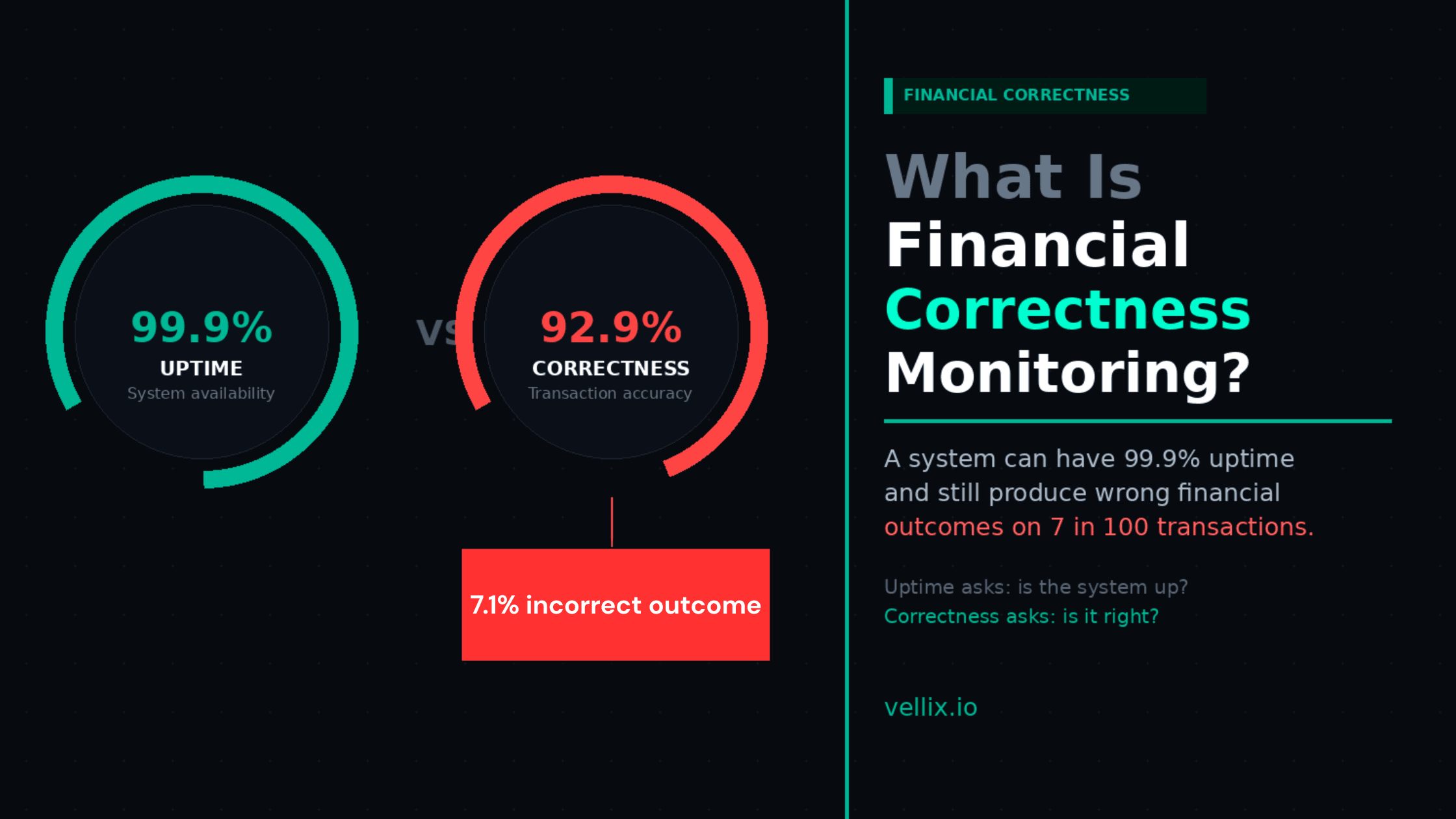
Step 4: Monitor for financial correctness, not just uptime
Most monitoring is infrastructure monitoring — CPU usage, error rates, response times. These metrics tell you when your system is down or slow.
They don't tell you when your system is producing incorrect financial outcomes while appearing healthy. A payment gateway that processes transactions but silently miscalculates settlement amounts will show green on every standard monitoring dashboard.
Financial correctness monitoring means comparing what your system recorded against what it should have recorded: initiated amount vs settled amount, order state vs payment state, ledger balance vs actual movement. These checks should run continuously, not just in testing.
The Shift in Mindset
Preventing production bugs requires a shift from reactive to proactive quality engineering.
Reactive: We test what we built, ship it, and fix what breaks.
Proactive: We map how it can fail, test those failures first, and monitor for them continuously.
The reactive approach produces postmortems. The proactive approach produces reliability.
In a fintech product, reliability is not a technical metric. It is the reason customers stay, the reason enterprise clients sign contracts, and the reason investors have confidence in your infrastructure.
Where AI-Powered Test Generation Fits In
The largest barrier to proactive quality engineering is the domain knowledge required to map failure modes. Not every QA team has engineers who know the specific ways UPI transactions fail, or how stablecoin reserve mechanics break under stress, or where KYC onboarding flows drop users silently.
This is the problem Vellix was built to solve. By providing AI-generated test scenarios trained on domain-specific failure patterns across fintech systems, Vellix gives teams access to the failure mode knowledge that previously required years of production experience to accumulate.
It doesn't replace the QA engineer. It gives the QA engineer the map.
Try it at app.vellix.io.
Abhijeet Batsa is the founder of Vellix.io and FuturestaQ. He spent 16 years building software products, payment, transactional flows and investment infrastructure at Paytm Money, Snapdeal, and Rakuten Viki.