By Abhijeet Batsa
Everyone is using AI to generate test cases now. That's table stakes in 2025.
The more interesting question is: what kind of test cases are they generating?
There's a difference between test cases that cover the happy path and obvious negatives — and test cases that catch the failure modes that only show up when real money moves between real systems under real load.
I spent time running the same payment API spec through four tools: ChatGPT, Cursor, Claude (free tier), and Vellix. Same input. Different outputs. The differences are more revealing than you'd expect.
The Setup
I used a standard payment initiation API — the kind any fintech or D2C platform with a payment gateway integration would have. The spec covers:
Payment initiation (UPI, card, net banking)
Webhook handling (success, failure, pending)
Refund initiation
Transaction status fetch
This is a real-world API surface. Every fintech team needs tests for this. The question is what "good tests" actually looks like for a payment flow.

What it does well:
ChatGPT is genuinely impressive for getting started fast. Give it your API spec or a plain English description of your payment flow, and it will generate structured test cases in any format you want — Gherkin, JSON, a table, a Postman collection, whatever your team uses.
It handles the obvious cases cleanly:
✅ Valid UPI payment initiation with correct payload
✅ Missing required field returns 400
✅ Invalid card number format
✅ Webhook received after successful payment
✅ Refund initiated for completed transaction
It's fast. It's format-flexible. It's good at turning requirements into structured documentation.
Where it falls short:
ChatGPT has no knowledge of how payment systems actually fail in production. It generates the test cases a junior QA engineer would write on day one — correct, reasonable, and insufficient.
Ask it to test your UPI payment API and it will not, on its own, generate:
What happens when the UPI app times out after 30 seconds but the payment is still in-flight at the PSP layer
What happens when your webhook arrives before the payment status is settled at the PG
What happens when the same txn_id is submitted twice due to a client retry — and one goes through
What happens when net banking returns a "pending" status that your frontend treats as a failure and the user pays again
These are not edge cases. These are common production failure modes. ChatGPT doesn't generate them because it has no domain training on payment failure patterns. It generates test cases based on the surface of your API, not based on what breaks in production.
You still need a payment expert to tell it what to test. Then it helps you write the tests faster.
Verdict: Great test documentation assistant. Not a domain expert.

What it does well:
Cursor is a different beast entirely. It's an IDE, not a chat interface. Its superpower is that it understands your existing codebase — not just the spec you paste into a prompt, but your actual implementation files, your page objects, your existing test structure, your framework conventions.
For unit test generation from existing code, it's excellent. If you have a payment service class written, Cursor can generate unit tests for it that match your testing framework, follow your patterns, and cover the branches in your code.
It's also good at test maintenance — when your API changes, Cursor can help update your existing tests to match.
Where it falls short:
Cursor is code-first. It generates tests based on what's in your code, not based on what happens in production payment infrastructure.
Real payment testing isn't about testing your code in isolation. It's about testing the interactions between your code, the payment gateway, the banking network, and the settlement system — under conditions your code has never seen.
Cursor will generate a test for your initiatePayment() function. It will not generate a test for what happens when Razorpay returns HTTP 200 but the payment is still in a "created" state instead of "authorized" — a real response pattern that causes double-payment bugs.
There's also a practical issue: for payment security tests specifically, engineers who've tried Cursor for this report still preferring manual creation. The domain knowledge gap is too wide for general code assistance to bridge.
Verdict: Exceptional for unit tests from existing code. Wrong tool for payment integration testing.

What it does well:
Claude's reasoning capability makes it noticeably better than ChatGPT at thinking through failure scenarios when you prompt it well. If you give it context — "we're testing a Razorpay integration, here are the known PG response codes, now generate edge cases" — it reasons through the problem more thoroughly.
It's also better at questioning assumptions. Ask Claude to generate test cases for your payment flow and it will sometimes ask: "What happens if the webhook is delayed? Should I include tests for idempotency?" ChatGPT tends to just generate.
It produces clean, well-structured output and understands testing concepts at a high level.
Where it falls short:
Claude is a general-purpose reasoning model. It knows about payment systems the way a smart generalist knows about any domain — enough to have a conversation, not enough to know what actually breaks.
The quality of output is highly dependent on how much domain context you provide in the prompt. With a minimal prompt ("generate test cases for my payment API"), the output is similar to ChatGPT — competent but generic. With a very detailed prompt including PG documentation and failure mode context, it does better — but now the work is on you, not the tool.
It also has no memory of the payment failure modes that surface from real transaction data. It can reason about failure modes you describe. It cannot surface failure modes you don't know about.
Verdict: The best general-purpose reasoner of the three. Still requires you to know what to ask for.

What it does differently:
Vellix is not a general-purpose AI. It's trained specifically on payment API failure patterns — built from production failure data, not from the internet.
The difference shows immediately.
Give Vellix the same payment API spec and it generates test cases that none of the other three tools produce without extensive prompting:
Idempotency under retry: Two identical payment requests arrive with the same order_id — does your system process them once or twice?
Webhook race condition: Webhook arrives before your database write completes — does your system handle out-of-order events?
Partial capture: Authorization succeeds but capture fails silently — does your reconciliation system catch this or does it report the payment as complete?
Currency precision: ₹1,00,000.00 vs ₹100000 vs ₹100000.0 — does your system handle all three correctly across all modes?
Net banking pending loop: User completes net banking on the bank side, PG is still processing, user hits back and retries — now you have two transactions in flight for the same order
UPI timeout with in-flight payment: The 30-second UPI app timeout expires, your frontend shows failure — but the payment completes at the PSP 45 seconds later
Refund against pending transaction: User requests refund before payment fully settles — what does your system do?
These are failure modes that come from production. Not from reading API documentation.
Vellix also generates directly into your framework — not a template you have to adapt, but actual test code in the language and framework your team uses, ready to run.
Time to output: 60 seconds from API spec to a complete test suite across all payment scenarios.
The Real Comparison
Here's the honest summary:
|
ChatGPT |
Cursor |
Claude Free |
Vellix |
| Speed |
Fast |
Fast |
Fast |
60 sec |
| Format flexibility |
High |
High |
High |
Framework-native |
| Happy path coverage |
✅ |
✅ |
✅ |
✅ |
| Standard negative cases |
✅ |
✅ |
✅ |
✅ |
| Codebase context |
❌ |
✅ |
❌ |
✅ |
| Payment domain knowledge |
❌ |
❌ |
❌ |
✅ |
| Production failure modes |
❌ |
❌ |
❌ |
✅ |
| Idempotency testing |
Needs prompting |
Needs prompting |
Needs prompting |
Built-in |
| Webhook race conditions |
❌ |
❌ |
❌ |
✅ |
| Reconciliation edge cases |
❌ |
❌ |
❌ |
✅ |
| Requires expert prompting |
Yes |
Partial |
Yes |
No |
What This Means Practically
If you're building payment features and you're using ChatGPT or Claude to generate your test cases, you're probably getting 60–70% coverage of the obvious scenarios. That's genuinely useful. It's faster than writing from scratch.
What you're not getting is the 30% of scenarios that cause actual production incidents.
The UPI timeout that creates a double-payment.
The webhook that arrives out of order and marks a failed payment as success.
The refund that processes against a transaction that hasn't settled.
The retry that creates duplicate orders.
These are the failure modes that don't show up in documentation. They show up in production logs, in reconciliation mismatches, in customer complaints, in chargebacks.
General-purpose AI tools generate test cases from the surface of your system. Domain-specific tools generate test cases from knowledge of how the category of system actually fails.
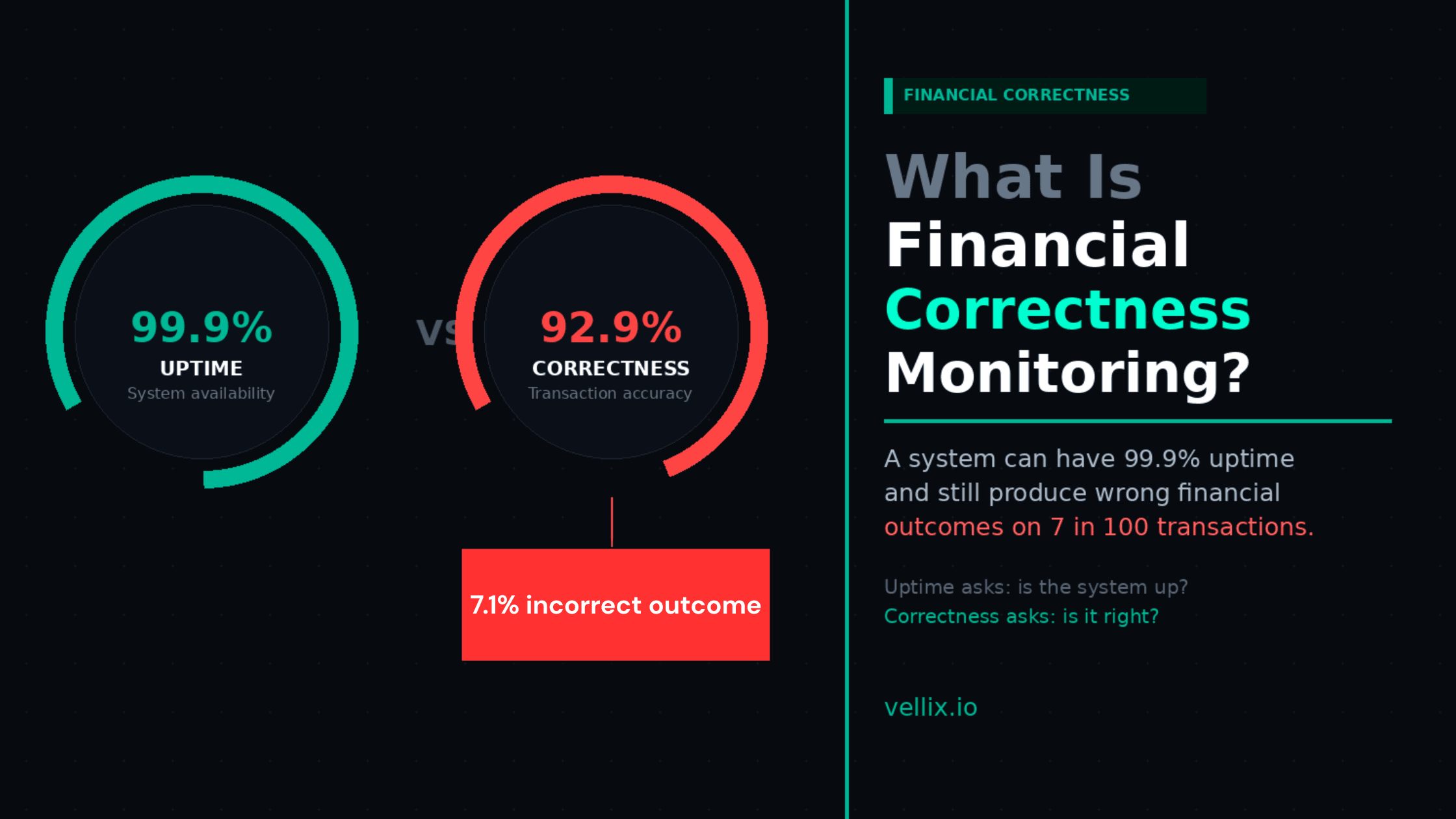
For most software, the difference is acceptable. For payment systems, where every failure mode has a financial consequence, the difference is the whole point.
The Bottom Line
Use ChatGPT or Claude to accelerate your documentation, structure your test plans, and generate the obvious scenarios faster.
Use Cursor to write unit tests for your payment service classes while your code is open.
Use Vellix when you need to know what actually breaks in a payment integration — before it breaks in production.
The free audit is at vellix.io/audit. Paste your API spec and see what it surfaces. You'll know within 60 seconds whether there are gaps your current test suite isn't covering.
Abhijeet Batsa is the founder of Vellix and FuturestaQ. He has 16 years of payment reliability experience at Paytm Money, Snapdeal, Paytm Insurance, and Rakuten Viki.